

Вступление#
Одним из главных испытаний при создании сетевых игр является ситуация, когда большое количество игроков собираются в одном месте и видят друг друга. В этом случае объём сетевых данных растёт не линейно: каждый игрок должен получать обновления обо всех остальных. Например, 100 игроков порождают уже около 10 000 индивидуальных обновлений.
Давайте посмотрим чем отличается Iris от стандартной системы репликации, Epic Games описывают Iris как:
Iris is an opt-in replication system that works alongside Unreal Engine’s existing replication system. The system builds on Epic’s experience with Fortnite Battle Royale, which supports up to 100 players per server instance. Iris supports robust multiplayer experiences with:
- Larger, more interactive worlds.
- Higher player counts.
- Lower server costs.
Способ тестирования#
Основная идея: небольшая плоскость — 2 км × 2 км.
В радиусе 800 метров от центра появляется 100 игроков, которые бегут к центру, постепенно становясь видимыми друг для друга.
Снимаем метрики и анализируем данные.
В лучших традициях стресс-теста отключаем всё ненужное:
- Коллизии между персонажами —
Pawncollision profile - Игнорируем
Cameratrace channel дляPawn - Коллизии скелетных мешей —
CharacterMeshcollision profile
Техническая реализация:
- Собираем Linux-сервер и Linux-клиент.
- Пакуем их в Docker-образы.
- Покупаем кучу виртуалок:
- Сервер: 2 vCPU Intel® Xeon® Processor 6354, 2 GB RAM — на отдельной VM.
- Клиенты: можно запускать по несколько штук на одной VM.
- Сервер запускается с параметром
-MaxPlayers=101. Игра не начинается, пока не подключатся 80 % клиентов. После этого вызываетсяGameState->HandleBeginPlay();, и все они устремляются к центру карты. - Через ~5 минут теста сервер останавливается, логи и данные профайлера выгружаются в S3.
- Удаляем все купленные виртуалки.
- Скачиваем
*.utraceи анализируем с помощью Unreal Insights.
В репликации будут участвовать:APlayerCharacter, UCharacterMovementComponent, APlayerController, APlayerState и AGameState.
Основную нагрузку, конечно же, будут создавать APlayerCharacter и UCharacterMovementComponent.
Стандартная система репликации#
Старый добрый друг — с нами он ещё с Unreal Engine 4.
Логику его работы можно было заменить на Replication Graph, чтобы изменить, кому, что и когда реплицировать.
Но Replication Graph рассматривать не будем, так как он считается устаревшим, а стандартная реализация больше служит примером, чем рабочим решением «из коробки».

Видим, что FrameRate в среднем колеблется от 10 до 15, а это ведь просто передвижение. Выбираем кадр со средним значением и смотрим, что же там внутри.

Выделим три основные категории в FEngineLoop::Tick (83.9 ms):
- Net Tick Time (13.3 ms) — обработка и парсинг входящих данных RPC
- Tick Time (3.5 ms) — Tick игровой логики и физики
- NetBroadcastTickTime (66.2 ms) — подготовка и отправка исходящих данных, проверка изменений внутреннего состояния реплицируемых объектов.
Net Tick Time (13.3 ms)#

Всё, что находится ниже Blueprint Time (28.9 µs), — это уже вызов RPC-функции, которая не относится напрямую к системе репликации. Это конечная реализация игровой логики компонента, в данном случае — UCharacterMovementComponent. Правее виден ещё один вызов RPC — ServerUpdateCamera (2.2 µs): это APlayerController передаёт положение и поворот камеры.
В этом тике общий Blueprint Time внутри Net Tick Time (13.3 ms) составил 8.5 ms, или примерно 64%.
Tick Time (3.5 ms)#
В разрезе репликации тут ничего интересного не происходит: тикают акторы и компоненты, просчитывается физика. Основной пожиратель времени кадра в нашем случае — SkinnedMeshComp Tick, его время выполнения напрямую зависит от того, насколько тяжеловесным окажется Animation Blueprint (в нашем случае это Manny_Simple из стандартного набора Unreal Engine 5).
USpringArmComponent тикает даже на выделенном сервере и трейсит геометрию для пересечения с камерой. Занимает 0.8 ms. А если учесть, что он прикреплён к капсуле, то во время Char PerformMovement происходит обновление и USpringArmComponent с UCameraComponent — 0.17 ms. Получается, тратим в сумме около 1 ms, при этом положение камеры передаётся через APlayerController, а USpringArmComponent на сервере не нужен вовсе.NetBroadcastTickTime (66.2 ms)#
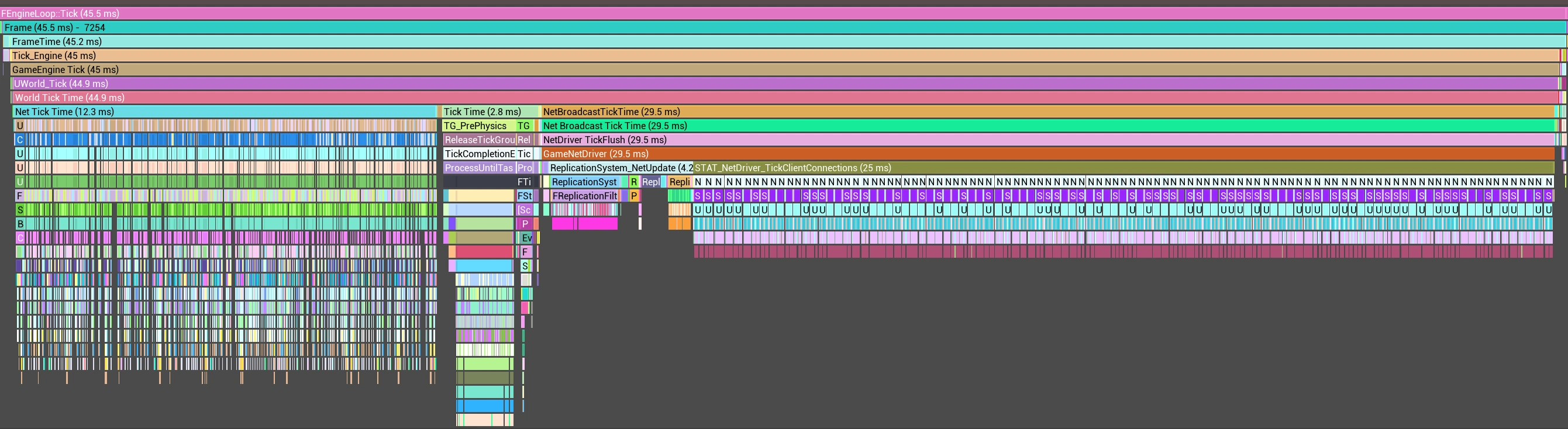
Здесь вызывается Process Prioritized Actors для каждого клиента, внутри которого вызывается Replicate Actor для каждого релевантного актора. Получается, в этом тике Process Prioritized Actors вызывается 101 раз: 100 виртуалок + 1 клиент, чтобы наблюдать за процессом со стороны. Replicate Actor вызывается ещё более 100 раз — 101 раз для ACharacter, 1 раз для APlayerController, несколько раз для AGameState и APlayerState, а также для всех остальных игровых сущностей. AGameState и APlayerState не реплицируются по 100 раз всем, потому что NetUpdateFrequency контролирует, как часто их нужно реплицировать.
AGameState— часто реплицируетdouble ReplicatedWorldTimeSecondsDouble;APlayerState— часто реплицируетuint8 CompressedPing;
В конце вызывается NetDriver_TickClientConnections (2.1 ms), который отправляет все получившиеся пакеты в сетевой сокет.
Iris Replication System#
Активируем Iris Plugin, подключаем его в DefaultEngine.ini и добавляем как C++ зависимость:
;; DefaultEngine.ini
[SystemSettings]
net.SubObjects.DefaultUseSubObjectReplicationList=1
net.IsPushModelEnabled=1
net.Iris.UseIrisReplication=1
net.Iris.PushModelMode=1
// MyGame.Build.cs
using UnrealBuildTool;
public class MyGame : ModuleRules
{
public MyGame(ReadOnlyTargetRules Target) : base(Target)
{
PCHUsage = PCHUsageMode.UseExplicitOrSharedPCHs;
/*
PublicDependencyModuleNames...
PrivateDependencyModuleNames...
*/
SetupIrisSupport(Target);
}
}
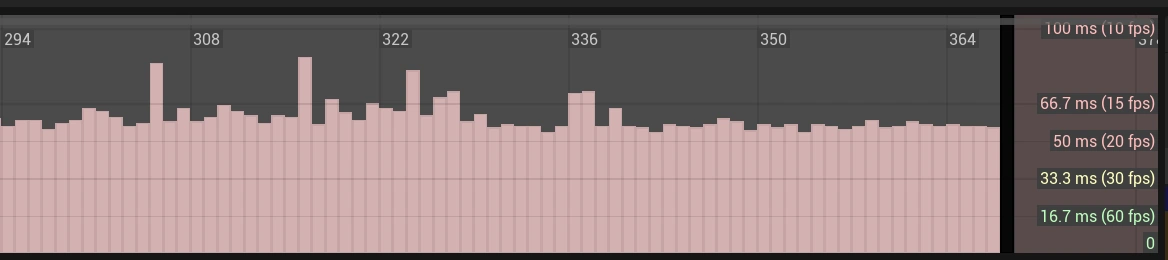

Первое, что бросается в глаза, — это то, что FrameTime не такой рваный, и мы находимся в зоне 15–20 FrameRate.
Смотрим изменения FEngineLoop::Tick (83.9 ms → 60.1 ms) = 23.8 ms:
- Net Tick Time (13.3 ms → 10.2 ms) = 3 ms (~23%)
- Tick Time (3.5 ms → 3 ms) = 0.5 ms — не думаю, что это заслуга Iris.
- NetBroadcastTickTime (66.2 ms → 45.8 ms) = 20.4 ms (~30%)
Неплохо для двух строчек в конфиге.
Можно провести аналогию с предыдущей реализацией: NetConnection Tick вызывается один раз для каждого клиента — это 101 вызов в этом кадре.
Внутри FReplicationWriter_Write происходит запись всех изменений, которые должен получить клиент. Здесь два вызова FReplicationWriter_Write — мне кажется, это потому, что данные пишутся, пока есть свободное место в буфере. Как только оно заканчивается, данные отправляются в сокет. Но так как остаются ещё данные для отправки, они записываются во второй пакет, который отправляется в конце NetConnection Tick.

Можно заметить, что FReplicationWriter_PrepareWrite и FReplicationWriter_FinishWrite отъедают больше половины UDataStreamChannel_Tick, при том что, по логике, основная работа приходится на FReplicationWriter_Write.
struct FScheduleObjectInfo
{
uint32 Index;
float SortKey;
};
UDataStream::EWriteResult FReplicationWriter::BeginWrite(const UDataStream::FBeginWriteParameters& Params)
{
IRIS_PROFILER_SCOPE(FReplicationWriter_PrepareWrite);
// ... code ... code ...
// $IRIS TODO: LinearAllocator/ScratchPad?
// Allocate space for indices to send
// This should be allocated from frame temp allocator and be cleaned up end of frame, we might want this data to persist over multiple write calls but not over multiple frames
// https://jira.it.epicgames.com/browse/UE-127374
WriteContext.ScheduledObjectInfos = reinterpret_cast<FScheduleObjectInfo*>(FMemory::Malloc(sizeof(FScheduleObjectInfo) * NetRefHandleManager->GetCurrentMaxInternalNetRefIndex()));
WriteContext.ScheduledObjectCount = ScheduleObjects(WriteContext.ScheduledObjectInfos);
}
void FReplicationWriter::EndWrite()
{
IRIS_PROFILER_SCOPE(FReplicationWriter_FinishWrite);
// ... code ... code ...
FMemory::Free(WriteContext.ScheduledObjectInfos);
WriteContext.ScheduledObjectInfos = nullptr;
WriteContext.bIsValid = false;
}
sizeof(FScheduleObjectInfo) = 8 байт, а GetCurrentMaxInternalNetRefIndex() = 65535. Итого: 524 280 байт выделяется и освобождается 101 раз за кадр.
Так как ScheduledObjectInfos используется просто как промежуточный буфер для индексов, я написал код, чтобы UReplicationSystem держал указатель на память, а FReplicationWriter её использовал. Также есть вероятность, что GetCurrentMaxInternalNetRefIndex() может измениться — я обработал это событие. Так как автор использует FMemory::Malloc, значит, и мне после использования не нужно как-то обнулять память. Данные в ScheduledObjectInfos сначала записываются, а только потом читаются.
Получилось как-то так
void FReplicationWriter::SetNetObjectListsSize(FInternalNetRefIndex NewMaxInternalIndex)
{
// ... code ... code ...
ReplicationSystemInternal->ReserveScheduledObjectIndices(sizeof(FScheduleObjectInfo) * NewMaxInternalIndex);
}
UDataStream::EWriteResult FReplicationWriter::BeginWrite(const UDataStream::FBeginWriteParameters& Params)
{
// ... code ... code ...
WriteContext.ScheduledObjectInfos = static_cast<FScheduleObjectInfo*>(ReplicationSystemInternal->GetScheduledObjectIndices());
WriteContext.ScheduledObjectCount = ScheduleObjects(WriteContext.ScheduledObjectInfos);
}
Patched Iris Replication System#
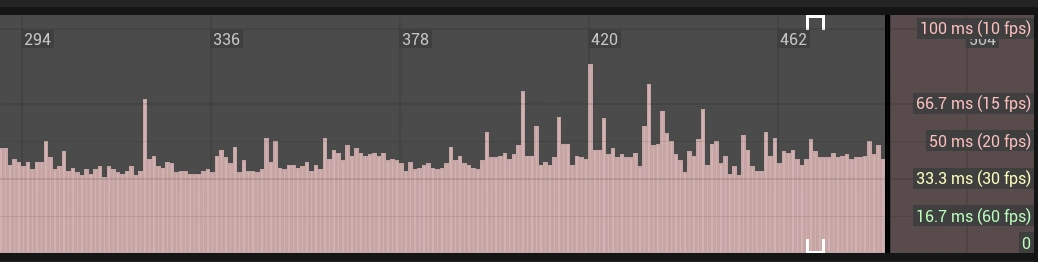
- NetBroadcastTickTime (66.2 ms → 29.5 ms) = 36.7 ms (~55%)
Финальные Shipping-испытания#
Включаю поддержку CsvProfiling для Shipping и увеличиваю тикрейт сервера до 120 FPS.
[/Script/OnlineSubsystemUtils.IpNetDriver]
NetServerMaxTickRate=120
Выводы#
- Iris обеспечил на 31% больший FrameRate и 24% меньший FrameTime в таком сценарии использования.
- Обе системы показали себя хорошо в этом сценарии.
- Всегда измеряйте производительность в условиях, приближённых к реальным.
- Unreal Insights потребляет значительное количество ресурсов:
-TraceFile -Trace=Cpu,Net -NetTrace=1 -StatNamedEvents. - Отключайте тик или удаляйте
USpringArmComponentна Dedicated Server. - Чем выше тикрейт сервера, тем больше исходящего трафика он генерирует. Например, за 5 минут работы теста при 30 FPS исходящий трафик составлял около 600 MB, а при 70+ FPS — уже около 900 MB.
Честно говоря, я ожидал другого результата. Эксперименты стоит продолжить — добавить больше реплицируемых сущностей и сделать сценарий ближе к реальной игровой ситуации.